Astera Labs has announced the Scorpio X-Series 320 Lane Smart Fabric Switch, the industry’s largest open, memory-semantic fabric switch now shipping to leading hyperscalers, featuring embedded Hypercast and In-Network Compute engines designed to reduce collective operation overhead for large-scale AI model inference. The launch represents a strategic shift from connectivity infrastructure to active compute participation, positioning fabric switches as a direct lever for improving accelerator utilization and token economics at the scale of production AI deployments.
What is Covered in This Article:
- Astera Labs’ Scorpio X-Series 320 Lane Smart Fabric Switch launch
- How Hypercast targets the mixture-of-experts collective operation bottlenecks
- In-Network Compute as an emerging capability within switch silicon
- Open ecosystem positioning against proprietary interconnect architectures
- COSMOS software’s role in production-scale AI resilience and deployment
The News: Astera Labs, Inc. announced the Scorpio™ X-Series 320 Lane Smart Fabric Switch on May 5, 2026, describing it as the industry’s largest open, memory-semantic fabric switch engineered to support large-scale AI infrastructure. The switch is shipping to leading hyperscalers, with production ramp targeted for the second half of 2026, and will be demonstrated at Computex 2026 in Taipei. Astera Labs also expanded its Scorpio P-Series PCIe fabric switch family to span configurations from 32 to 320 lanes, making it the broadest family of PCIe 6 fabric switches available and giving data center architects a wider range of topology options across diverse accelerator platforms.
The Scorpio X-Series introduces two hardware-accelerated engines: Hypercast, a data replication engine designed to accelerate AllGather, AllScatter, and All-to-All collective operations, and an In-Network Compute engine that offloads AllReduce and ReduceScatter operations from accelerators directly onto the switch silicon.
“The Scorpio X-Series 320 Lane high-radix AI fabric switch replaces multiple legacy switches to enable larger scale-up cluster sizes in a single hop and reduce overall latency,” said Jitendra Mohan, Chief Executive Officer of Astera Labs.
Astera Labs Turns the AI Switch Into an Inference Accelerator
Analyst Take: The Scorpio X-Series launch signals a meaningful evolution in how AI infrastructure vendors are defining the role of the fabric switch. Rather than competing on raw bandwidth or port density alone, Astera Labs is embedding compute intelligence directly into the switching silicon in response to the specific demands of mixture-of-experts (MoE) architectures that now dominate frontier model development. The central claim underlying the Astera Labs Scorpio AI fabric switch launch is that the fabric has become a deterministic constraint on token economics, and that addressing it requires purpose-built, in-network intelligence rather than incremental improvements to general-purpose switching.
Astera Labs’ revision of its scale-up switching market projection to $20 billion by 2030 — nearly four times its October 2024 estimate of $5 billion — reflects both the accelerating pace of large-scale AI deployments and the company’s significantly expanded product ambitions in this segment. At the start of the year, we predicted scale-up networking to be the focal point of GPU optimization, and this revision suggests that Astera has visibility into the rack-level innovation at the heart of AI co-design.
Hypercast and the MoE Collective Operation Problem
The rise of MoE architectures in frontier AI model development has revealed a core limitation in conventional fabric switches. MoE models send each token through a small, dynamically chosen group of specialized sub-networks, and because that group is not known until the router makes its selection, switches cannot set up the required data paths in advance. Astera Labs’ Hypercast engine is built around this problem, delivering fast, predictable group configuration where legacy open protocol switches have historically been slow and inconsistent.
Three Scenarios for MoE Routing
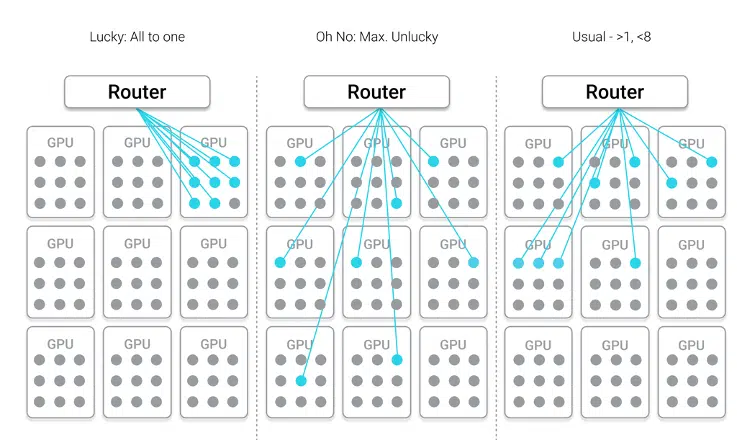
The technical blog accompanying the launch describes the two options that legacy switches leave system designers with: either each GPU sends redundant copies of its data — wasting bandwidth and stalling compute — or the switch is reconfigured on the fly, a process that can take tens of milliseconds across dozens of expert layers in a single model pass. For example, DeepSeek V3 designers were forced to cap token routing at 4 destination nodes at inference time simply to stay within their interconnect’s capacity, directly limiting what the model could do. By removing the routing cap that legacy interconnects impose, Hypercast gives model designers access to the full combinatorial space of expert groupings their architecture demands rather than a constrained subset their interconnect can tolerate.
In-Network Compute as a Structural Architecture Shift
The addition of an In-Network Compute engine to the Scorpio X-Series reflects a broader trend of moving computational functions out of the accelerator and into adjacent silicon — a pattern already visible in data processing units (DPUs) and smart network interface cards (NICs) in the scale-out network. For Astera Labs, the specific offload targets are the AllReduce and ReduceScatter collective operations, which require each GPU to send its data to all participating devices, aggregate the results, and return them. By performing the reduction directly on the switch silicon, Astera Labs claims to reduce GPU IO for these collective operations by up to 49%, effectively freeing accelerator resources to be applied to token generation rather than communication management.
The tokens-per-watt framing the company uses to describe this benefit is strategically significant because it reframes the value of connectivity infrastructure from a networking cost center into a direct contributor to the efficiency metrics that AI labs and hyperscalers use to evaluate total cost of ownership. The claim repositions the fabric switch as an active participant in AI compute rather than a passive conduit, and that repositioning pushes advanced networking as a key driver of TCO for frontier clusters.
Open Ecosystem Positioning Against Proprietary Interconnects
Astera Labs has consistently positioned the Scorpio family around open protocols rather than proprietary interconnect architectures, and the 320 Lane launch extends this stance with explicit software-defined integration across leading merchant and custom silicon. This approach stands in contrast to closed proprietary fabrics, where accelerator upgrades often require forklift replacements of the interconnect alongside the compute. The expanded Scorpio P-Series, now spanning 32 to 320 lanes, signals that Astera Labs is targeting not just the highest-scale single-hop configurations but the full topology spectrum from modular server appliance architectures to multi-rack 512-GPU clusters.
Memory-semantic connectivity lets accelerators read and write to fabric resources the same way they access local memory, removing the software layer that traditional message-passing protocols require. Whether this translates to the ecosystem adoption Astera Labs is projecting will depend on how quickly accelerator vendors and system integrators prioritize qualifying the platform within their own design cycles. The $20 billion scale-up switching market projection for 2030 signals a significant shift away from direct-attach topologies, a transition we are already seeing among AI labs, hyperscalers, and neoclouds moving large-scale production workloads onto switched architectures.
Adapting to Heterogeneity
The diversity of accelerators now in active deployment has made a one-size approach to switching increasingly unworkable, with virtually every platform carrying at least some form of PCIe support while varying considerably in the scale-up topology each requires. Astera Labs noted in our briefing that this variance drove the deliberate breadth of the Scorpio switch family — spanning 32 to 320 lanes across devices — specifically because no single configuration can address the full spectrum of architectures being deployed across AI labs and hyperscalers today. The shift from training-dominated clusters toward a greater proportion of inference workloads has added further complexity, since the optimal cluster size, GPU memory configuration, and interconnect topology differ materially across use cases, making the case for a portfolio approach stronger than a strategy built around a single flagship switch.
Astera Labs has publicly cited a design principle captured in the phrase that 99% of links in a large-scale deployment will function correctly but that the remaining 1% will consume the majority of deployment time. The COSMOS-integrated smart capture capability, which performs protocol-layer analysis directly in silicon, provides operators with real-time performance telemetry and fault localization without requiring external monitoring infrastructure. The unified software stack across re-timers, fabric switches, copper connectivity, and optical solutions reflects an intent to manage composable AI infrastructure from a single control plane, a design objective with potential operational advantages in environments running multiple interconnect generations simultaneously. As rack compositions grow more diverse, spanning multiple accelerator types, configurations, and cluster scales up to 512 GPUs, the case for a coherent networking layer that flexes across all of them without forcing architectural trade-offs becomes increasingly essential for infrastructure teams to invest in.
What to Watch:
- How quickly hyperscaler and AI lab deployments translate the 49% GPU IO reduction and 2x collective performance gains into measurable XPU utilization improvements across diverse model architectures and production workloads
- Which accelerator vendors and system integrators move first to qualify the Scorpio X-Series within their own XPU platform designs, and how that sequencing shapes early ecosystem momentum
- The rate at which the production ramp in the second half of 2026 scales to meet demand as XPU diversity across AI infrastructure continues to accelerate
- How far Astera Labs’ open, memory-semantic approach extends across the heterogeneous XPU landscape as AI labs push into gigawatt-class deployments where proprietary interconnect lock-in carries the highest switching cost
- What the Computex 2026 demonstrations of the Scorpio X-Series and PCIe 6 scale-up optics reveal about near-term integration timelines for XPU platforms not yet publicly confirmed as supported
See the full press release on Astera Labs’ Scorpio X-Series 320 Lane Smart Fabric Switch announcement on the company website.
Disclosure: Futurum is a research and advisory firm that engages or has engaged in research, analysis, and advisory services with many technology companies, including those mentioned in this article. The author does not hold any equity positions with any company mentioned in this article.
Analysis and opinions expressed herein are specific to the analyst individually and data and other information that might have been provided for validation, not those of Futurum as a whole.
Other Insights From Futurum:
Astera Labs Q4 2025 Earnings: Diversified AI Connectivity Momentum
Cisco’s Universal Quantum Switch: Will Interoperability Finally Unblock Quantum Networks?
Can Eridu’s AI Networking Break the Data Center Bottleneck—or Just Move It?
Image Credit: Astera Labs
Originally published by Futurum Group. Republished with attribution.




