Intel has launched the Xeon 6+ processor family (formerly codenamed Clearwater Forest), its first data center product manufactured on Intel 18A process technology and the first to use Foveros Direct 3D advanced packaging, delivering up to 288 efficient cores with 576 MB of last-level cache in a disaggregated tile architecture. The launch, paired with the new Ethernet E835 network adapter, represents Intel’s coordinated rack-scale strategy to define the compute and networking fabric for agentic AI infrastructure.
What is Covered in This Article:
- Intel’s first Intel 18A data center CPU with an industry-leading 288-core count
- Foveros Direct 3D packaging milestone enabling disaggregated tile architecture
- Agentic AI thesis positioning CPUs as orchestration engines over GPU FLOPS
- Rack-level product strategy pairing Xeon 6+, E835 networking, IPU, and Arc GPU reference designs
- Competitive positioning against AMD EPYC 9965 and Arm-based alternatives
The News: Intel announced the Intel Xeon 6+ processor family at Computex on June 1, 2026, marking the company’s first data center product manufactured on its Intel 18A process node and the first product in the industry to use Foveros Direct 3D advanced packaging technology. The flagship 6990E+ SKU delivers 288 efficient cores based on the new Darkmont architecture, 576 MB of last-level cache representing approximately 5x the prior generation, 12-channel DDR5 memory at 8000 MT/s, 96 PCIe 5.0 lanes, and 64 CXL 2.0 lanes, with a thermal design power ranging from 330W to 450W across the product stack.
Alongside Xeon 6+, Intel launched the Ethernet E835 Controllers and Network Adapters, delivering up to 200GbE bandwidth with port configurations from 2x25G to 1x200G, consuming approximately 47 percent lower power than the NVIDIA ConnectX-6 DX and approximately 80 percent lower power than the Broadcom BCM957508-P2100G at line rate under bidirectional load. The E835 implements RDMA via RoCEv2 and iWARP, SPDM 1.2 attestation for zero-trust architectures, and FIPS 140-3 Level 1 certification.
Intel positions both products as the foundation of its “Intelligence Center” infrastructure paradigm, where Xeon CPUs, Ethernet networking, and GPU acceleration form an integrated platform for agentic AI orchestration.
Kevork Kechichian, Executive Vice President and General Manager of Intel’s Data Center Group, stated that “As AI becomes more agentic, the constraints shift to orchestration, concurrency, and data movement. That shift reinforces a core reality: the CPU remains the control plane for the modern AI infrastructure. With Xeon 6+ and Ethernet E835, we’re tightly coupling compute and networking to reduce bottlenecks and enable efficient, secure scaling of real-world agentic workflows.”
Intel Xeon 6+ Targets Agentic AI Density With 288 E-Cores on Intel 18A
Analyst Take: The Intel Xeon 6+ launch redefines the role of Intel CPUs in the AI infrastructure stack by aligning with agentic workloads, with a simultaneous E835 Ethernet launch extending this thesis to the network fabric. This launch arrives at a critical juncture. Intel maintained 45.3% data center CPU market share in Q4 CY2025, according to Futurum’s 1H 2026 Data Center Semiconductors Forecast, but Arm-based alternatives surged to 25.0% with the data center CPU market on pace to grow 38.8% in 2026, driven by AI inference demand. Intel’s thesis that each step of an agent’s think-plan-act-reflect cycle requires different compute characteristics — with CPUs handling context retrieval, tool execution, policy enforcement, and orchestration while GPUs serve reasoning-intensive inference — derives from customer evidence that for multi-agent systems, core density and cache capacity take precedence. In a supply-constrained market, the central question is whether Intel’s combined Xeon 6+ and E835 platform can manifest in a rack-scale platform with a scale advantage over Arm-based alternatives and AMD’s EPYC roadmap.
Intel 18A and Foveros Direct 3D Deliver a Manufacturing Inflection Point
The Xeon 6+ is Intel’s first data center product on Intel 18A, employing both PowerVia backside power delivery and RibbonFET gate-all-around transistors, and it is the first product in the industry to use Foveros Direct 3D stacking, making it a dual proof point for Intel’s process and packaging technology roadmap. The disaggregated architecture places 12 compute tiles manufactured on Intel 18A atop three active base tiles fabricated on Intel 3, with two I/O tiles on Intel 7, all connected through EMIB 2.5D interconnect and Foveros Direct 3D vertical stacking that enables face-to-face die bonding with higher interconnect density than prior Foveros generations.

This chiplet approach allows Intel to optimize each functional block independently. The 288-core configuration in a single socket represents a 2x increase from the 144-core Xeon 6780E, achieved within a 450W thermal envelope that is only 36% higher than the prior generation’s 330W, yielding the claimed 1.55x performance-per-watt improvement that precisely matches the gain achieved by AMD’s Turin according to Phoronix testing.
Intel’s roadmap shows Diamond Rapids arriving in 2027 on Intel 18A-P with PCIe Gen 6, 50 percent more cores, and 2x memory bandwidth, suggesting Xeon 6+ sets a template for an annual cadence of CPU improvement. Intel 18A’s successful deployment at data center scale, combined with the Foveros Direct 3D packaging milestone, provides credibility for both Intel’s internal product roadmap and its foundry ambitions, where manufacturing process competitiveness has been the company’s most scrutinized capability gap.
Agentic AI Reframes the CPU Value Proposition Beyond FLOPS
Intel’s pre-COMPUTEX briefing explicitly distinguished between single-turn AI inference — which is “FLOPS-driven” with “minimal coordination” — and agentic AI, which is “continuous,” “flexibility and general-purpose driven,” and “coordination and execution-heavy,” a framing that directly challenges the prevailing narrative that AI infrastructure spending flows primarily to GPU accelerators. In Intel’s architectural model, each step of an agent’s operational cycle has distinct compute requirements: context retrieval demands memory bandwidth and capacity, reasoning may invoke sub-20-billion-parameter models directly on CPU or coordinate with GPUs for larger models, acting requires rapid tool-call turnaround and API transaction throughput, and governing enforces identity, policy, and guardrails across all operations.
Xeon 6+’s 576 MB last-level cache serves as a tool execution sandbox where agent state and context can reside without requiring main memory round-trips, while the 288-core count enables hundreds of concurrent agent threads with dedicated resources. Intel cites that agentic coding workloads generate up to 1,000x more tokens than single-turn interactions, creating system throughput pressure that rewards core density and memory bandwidth.
The company’s software stack investments in open-source AI framework support demonstrate that Intel is pursuing software-level optimization to ensure Xeon captures the orchestration and tool-execution portions of agent workflows that GPUs cannot efficiently serve. The takeaway is that Intel is attempting to expand the total addressable market for CPUs in AI by redefining which computational tasks belong on general-purpose processors versus accelerators, a thesis that the market is beginning to validate.
Intel’s grounds this case in customer data and internal R&D. In our analyst roundtable, Kechichian noted that Intel has profiled upwards of 300 agentic workloads spanning customer, partner, and internal deployments, observing CPU-to-agent ratios that range from a single CPU serving four to five lightweight agents at one extreme to a single complex agent consuming three to four CPU threads at the other. More telling than any single ratio is the directional trend of GPU-heavy prompt parsing toward the data movement and model loading that dominate multi-agent execution; the CPU-to-GPU balance compresses toward parity. “Agents per watt” is becoming a new metric to hill climb.
E835 Ethernet Extends the Efficiency Thesis to Network Fabric
The simultaneous launch of the Ethernet E835 alongside Xeon 6+ reflects Intel’s systems-level thesis that agentic AI workloads require coordinated optimization across compute, memory, and network layers rather than point-product supremacy in any single domain. Intel’s specific power efficiency claims provide a measurable differentiation story that compounds at rack scale, where Intel envisions up to 36,864 E-cores in a single liquid-cooled 30x2U configuration with dozens of network adapters per rack. The E835’s RDMA capabilities via RoCEv2 and iWARP directly address the rapid tool-call turnaround that multi-agent systems demand, while Dynamic Device Personalization enables intelligent packet processing that reduces CPU cycles spent on networking overhead.
Security features address enterprise requirements for device-level verification in zero-trust environments. The E835’s software reconfigurability through the Intel Ethernet Port Configuration Tool (EPCT), supporting configurations from 2x25G through 1x200G without revalidation, offers flexibility to discerning enterprise and telco customers. Intel’s coordinated Xeon 6+ and E835 launch constructs a platform-level efficiency and security narrative that single-component competitors cannot easily replicate, positioning Intel to capture value across multiple infrastructure layers simultaneously.
That multi-layer ambition is best understood as a contribution to the rack rather than to any single socket. Intel now treats the rack, not the discrete component, as the unit of competition. The enterprise conversation has shifted from socket-level specifications toward gigawatt-level questions about how compute, networking, and acceleration should be balanced, opening the door for Intel to leverage CPUs as an orchestrator for a broad array of proprietary server components.
Competitive Positioning Reveals Selective Advantages and Structural Risks
Intel’s competitive claims against AMD’s EPYC 9965 are carefully framed around per-thread metrics — 1.3x higher performance per thread and 1.3x higher performance per thread per watt — measured across workloads including server-side Java, WordPress, NGINX, databases, and 5G control plane, while the cryptographic differential is particularly stark at 15.2x faster SHA-512 encryption. This selective framing acknowledges that EPYC 9965 offers 192 cores with SMT (384 threads) at 500W while Xeon 6990E+ provides 288 physical cores without SMT at 450W, meaning Intel leads on physical core count, power efficiency, and cache capacity while AMD leads on logical thread count.
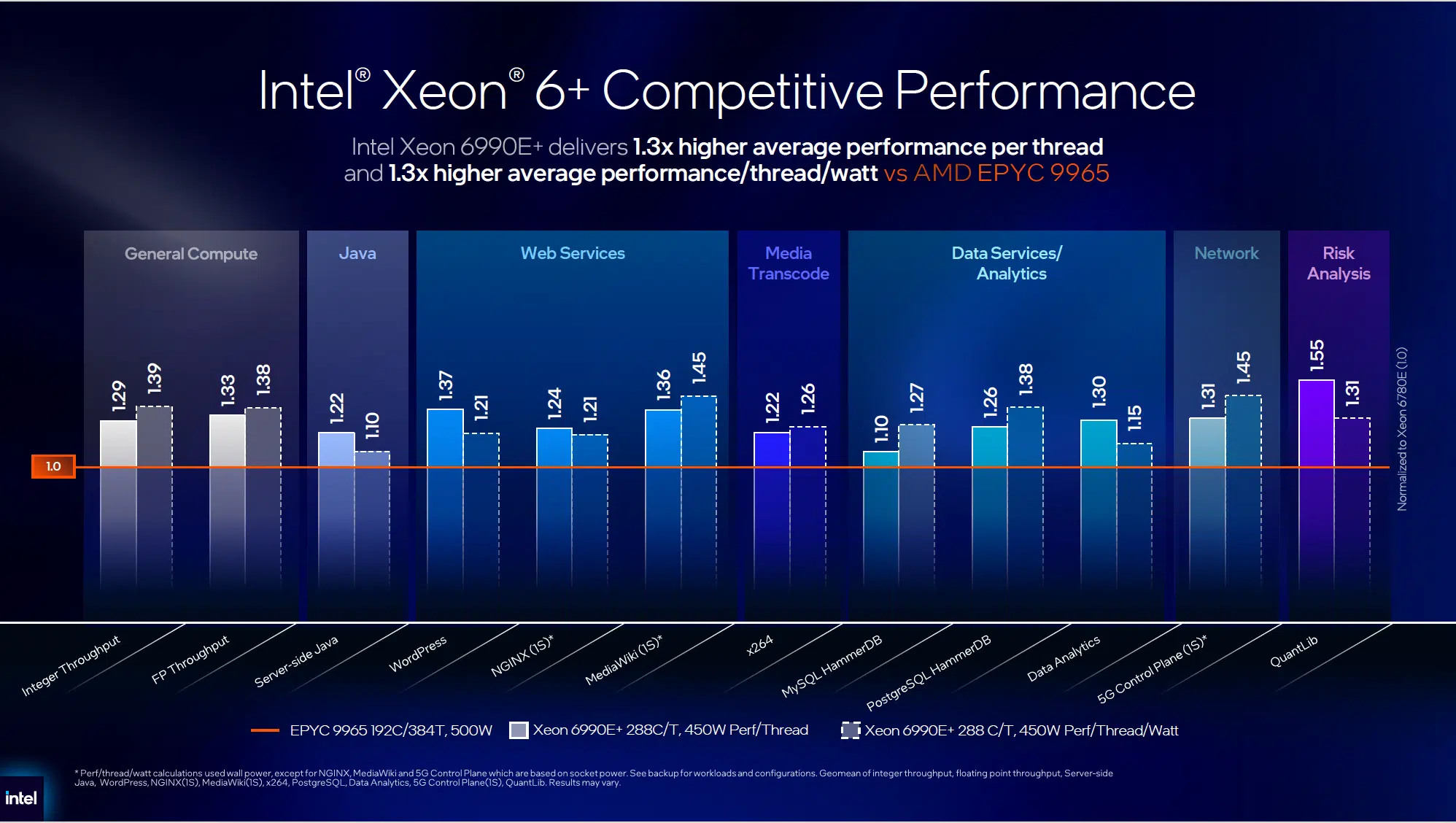
The more structural competitive risk emerges from Arm-based alternatives that captured the fastest share shift in data center CPU history. Intel’s ecosystem breadth provides distribution reach that Arm must build organically, but the custom silicon capabilities of hyperscalers increasingly allow them to bypass merchant CPU vendors entirely for standardized workloads. The 9:1 server consolidation ratio versus second-generation Xeon, translating to 79% fleet space reduction and 23 GWh of energy savings over four years, provides a compelling infrastructure refresh narrative for organizations operating aging x86 estates. Intel’s competitive moat depends on maintaining architectural differentiation in the high-density, security-sensitive, and orchestration-intensive workloads where its integrated features create capabilities that commodity core counts alone cannot replicate.
What to Watch:
- Whether Intel 18A yields and Foveros Direct 3D packaging ramp deliver sufficient volume to validate the captive manufacturing thesis as Xeon 6+ moves to broad OEM availability in the second half of 2026.
- How TSMC’s N2 and A16 capacity allocation decisions affect AMD, AWS, Google, and Microsoft’s ability to scale competing data center CPUs.
- Whether Arm-based alternatives capture agentic workloads through custom silicon before Intel’s density and manufacturing advantages take hold.
- How Ericsson’s reported 30% performance and 60% performance-per-watt gains on Xeon 6+ translate across broader telco and enterprise deployments beyond 5G core networks.
- Whether Intel’s Diamond Rapids sustains architectural momentum against AMD’s Turin Dense and Arm’s continued hyperscaler adoption.
See the full press release on Intel’s Xeon 6+ processor and Ethernet E835 announcements on the company website.
Disclosure: Futurum is a research and advisory firm that engages or has engaged in research, analysis, and advisory services with many technology companies, including those mentioned in this article. The author does not hold any equity positions with any company mentioned in this article.
Analysis and opinions expressed herein are specific to the analyst individually and data and other information that might have been provided for validation, not those of Futurum as a whole.
Originally published by Futurum Group. Republished with attribution.




